
77%. 우리나라 국민이 ‘포털’을 통해 뉴스를 접하는 비율이다. 영국 로이터저널리즘연구소의 발표처럼 포털로 뉴스를 보는 의존도가 압도적으로 높은 상황에서 어떤 기사를 노출할지에 대한 중요성이 커지고 있다. 현재 네이버, 다음, 구글 등에서 저마다의 알고리즘 시스템으로 뉴스를 배열하는 가운데, 한국언론진흥재단에서 좋은 뉴스를 골라주는 알고리즘을 개발했다.
한국언론진흥재단은 지난 5일 서울 태평로 프레스센터에서 ‘뉴스트러스트 알고리즘 개발의 의미와 전망’ 토론회를 열어 개발 중인 알고리즘의 내용을 공개하고 프로그램을 시연했다. 이 알고리즘은 지난 2016년 5월 전문가들이 모여 출범한 ‘뉴스트러스트 위원회’가 저널리즘적 가치를 구현한 뉴스를 선별하고, 이용자에게 필요한 기사를 제공하기 위해 만든 것이다.
뉴스트러스트 위원인 송해엽 군산대 미디어문학과 교수는 “현재 포털에서 정치, 사회, 경제, 국제 등 일반적으로 중요하다고 생각하는 뉴스보다 연예, 스포츠 등 상대적으로 가벼운 기사가 더 많이 노출되고 있다”라며 “어떻게 하면 더 좋은 뉴스를 이용자들에게 유통할 수 있는지에 대한 논의가 필요한 시점이다”라고 알고리즘 개발의 의의를 설명했다.
송 교수는 “기존 포털이 사용하는 알고리즘은 이용자들이 선호하는 뉴스를 골라 보여주는 방식"이라며 "뉴스트러스트 위원회에서 만든 것은 ‘어떤 기사를 사람들에게 보여줘야 하는가’에 대한 뉴스 자체의 저널리즘적 가치에 기반을 둔 ‘공적 알고리즘’”이라고 소개했다.
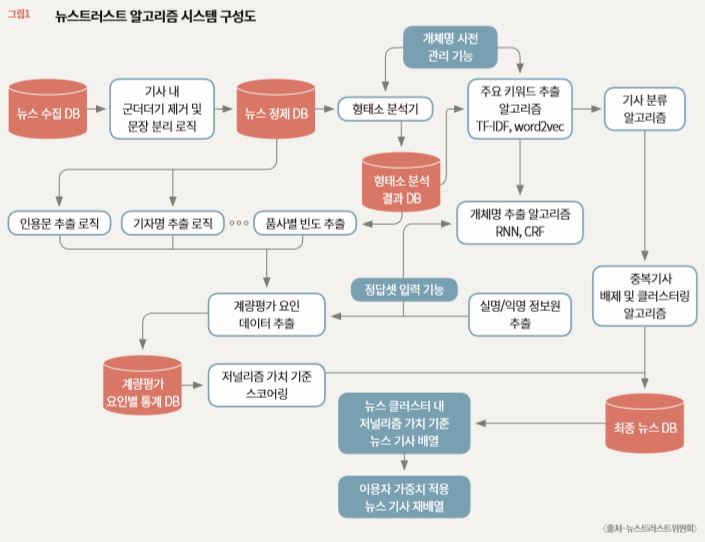
기사 길이?인용문 수?이미지 수 등 요인 계량화…점수 매겨 ‘좋은 뉴스’ 선별
오세욱 한국언론재단 선임연구위원 겸 뉴스트러스트 위원은 알고리즘 개발 내용에 대해 발표하고 직접 시연했다. 위원회는 1년여간 논의를 통해 뉴스 신뢰도를 구성하는 저널리즘 가치로 사실성, 투명성, 다양성, 균형성, 독창성 등 총 11개 특성을 꼽아 전체 모델을 개발했다. 이후 실제 사례 분석을 위해 13만여 건의 기사를 직접 알고리즘에 넣어 결과를 도출했다.
뉴스트러스트 알고리즘에 반영되는 요인은 △기자명 △기사의 길이 △인용문의 수 △제목의 길이 △제목의 물음표, 느낌표의 수 △수치 인용 수 △이미지의 수 △평균 문장의 길이 △제목에 사용된 부사 수 △문장당 평균 부사 수 △기사 본문 중 인용문의 비중 등으로, 이를 계량화하고 가중치를 더해 점수로 매긴다.
예를 들어 기자 실명이 들어가면 사실성과 투명성이 높다고 판단하고, 기사의 길이가 길고 인용문의 수가 많으면 ‘갖춰진 내용’이라고 보고 가점을 매긴다. 제목의 길이가 45자 이상이거나 물음표, 느낌표의 수가 많으면 이른바 ‘낚시성 기사’로 판단해 감점한다. 기사 내부에 사진 등 이미지가 있으면 정보성이 있어 긍정적으로 평가하지만, 3개 이상은 지나치게 많다고 판단하는 식이다.
기사 문법?소비 패턴의 변화 반영 안 돼…유통 아닌 뉴스 자체의 품질 문제도 지적
이날 토론자로 참석한 언론 관계자들은 저널리즘 가치를 반영한 ‘공적 알고리즘’을 개발하고, 좋은 기사를 판별하는 기준을 제시한다는 측면에서 대부분 긍정적 의견을 내놓았다. 그러나 해당 요인으로 기사를 평가했을 때 실제로 좋은 뉴스라고 판단할 수 있는지에 대한 의문을 공통적으로 제기했다.
이희정 한국일보 미디어전략 실장은 “기자 이름은 얼마든지 넣을 수 있기 때문에 평가의 대상이 될 수 없다”며 “기사의 길이 역시 성격에 따라 오히려 압축적인 게 좋을 수 있고, 이미지 역시 사진 20개가 들어갔지만 스토리텔링만 있다면 충분히 좋은 뉴스가 되기도 한다”는 생각을 밝혔다.
디지털 시대에 접어들며 이미지를 중심으로 한 카드뉴스, 영상뉴스 등 기사 문법과 소비 패턴이 바뀌는 상황에서 ‘글 기사’를 기준으로 만든 알고리즘의 한계에 대한 지적도 나왔다. 김양순 KBS 디지털뉴스팀장은 “최근 SNS나 유튜브 등을 통해 이미지나 영상으로 뉴스를 소비하는 방식이 늘어나고 있는데, 글이 아닌 기사는 어떻게 평가할 수 있을지 의문이 든다”고 말했다.
김동현 민중의소리 뉴미디어 국장 역시 “기존 매체가 생산한 기사를 원본으로 정보를 큐레이션 하는 매체들이 많이 생겨나고 있는데, 이런 뉴스는 어떻게 평가할지 모르겠다. 뉴스트러스트 알고리즘이 평가하는 요소는 과거의 방식에 초점이 맞춰져 있다”고 꼬집었다.

일부 토론자들은 기사 자체의 품질에 대한 근본적 의문을 제기하기도 했다. 김경모 연세대 언론홍보영상학부 교수는 “국내 언론이 생산하는 기사 전체의 질이 낮아진 상황에서 이번 알고리즘은 좋은 기사를 선별하는 것보다 ‘어뷰징’ 등 저품질 기사를 걸러내는 것에 방점이 찍혀 있는 것으로 보인다”고 말했다.
이 실장은 “이번 알고리즘은 뉴스의 유통 문제를 지적하지만, 기사 자체의 품질도 생각할 수밖에 없다”며 “현장에서 일하는 기자들이 좋은 기사를 쓰는 것이 최고의 목표인 조직에서 일하는가에 대한 질문을 하게 된다”고 덧붙였다.
오 위원은 “이번 알고리즘은 완성품이 아니라 중간 결과이며, ‘정답’이라고도 할 수 없는 하나의 방안으로써 제시한 것”이라며 “언론사, 일반 이용자 등에게도 연구 과정을 공개해 다양한 의견을 수렴한 뒤 향후 개발에 적극적으로 반영할 계획이다”라고 강조했다.
글. 양승희 이로운넷 기자
사진제공. 뉴스트러스트 위원회